Base64实现数据隐写的原理分析
在开始本篇文章前,让我们先来看一组base64编码的字符串,这组base64解码后的内容是daidrhouse。这看来似乎并没有什么问题。但是当你仔细观察时,你会发现第一行和第4行解码后的结果都是d,但编码内容竟然不太一样?
ZG==
YY==
aW==
ZF==
cm==
aM==
b2==
dc==
c2==
Zf==
按照正常的base64编码,daidrhouse应该得到下面的结果。
ZA==
YQ==
aQ==
ZA==
cg==
aA==
bw==
dQ==
cw==
ZQ==显然,与前者相比,每串base64的第二个字符都被改变了,但解码后的内容依然不变,这得从base64编码的原理说起。
什么是base64 ?
顾名思义,base64编码就是用64个ascii字符作为基础来编码二进制内容的一种编码方式。相信各位一定在网页中看到过base64编码的内嵌图片,甚至QQ音乐传输歌词文件时,也采用了base64编码。将二进制编码为ascii字符,使数据在某些场景下更便于阅读、便于传输。当然,将所有二进制「浓缩」到区区64个字符来表示,一定会在体积上作出妥协。字符在编码完成后,会增大1/3倍,至于原因,下面会讲到。
索引表
base64有一张标准编码表,为64个ascii字符排序并赋予索引。
| 索引 | 字符 | 索引 | 字符 | 索引 | 字符 | 索引 | 字符 |
|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w |
| 1 | B | 17 | R | 33 | h | 49 | x |
| 2 | C | 18 | S | 34 | i | 50 | y |
| 3 | D | 19 | T | 35 | j | 51 | z |
| 4 | E | 20 | U | 36 | k | 52 | 0 |
| 5 | F | 21 | V | 37 | l | 53 | 1 |
| 6 | G | 22 | W | 38 | m | 54 | 2 |
| 7 | H | 23 | X | 39 | n | 55 | 3 |
| 8 | I | 24 | Y | 40 | o | 56 | 4 |
| 9 | J | 25 | Z | 41 | p | 57 | 5 |
| 10 | K | 26 | a | 42 | q | 58 | 6 |
| 11 | L | 27 | b | 43 | r | 59 | 7 |
| 12 | M | 28 | c | 44 | s | 60 | 8 |
| 13 | N | 29 | d | 45 | t | 61 | 9 |
| 14 | O | 30 | e | 46 | u | 62 | + |
| 15 | P | 31 | f | 47 | v | 63 | / |
有时为了防止混淆(比如链接),会使用 . _ 来代替索引表中的 + / 。
编码方式
base64将3个字节(24位)作为一组进行处理。不足3字节时填充0,并在结尾使用 = 来标识填充的字节数。并将每6位作为1小组,将24位编码成4组6位二进制。此时,这6位二进制一共有 2^6=6426=64 种情况,正好能够用64个字符来表示。(这也解释了为什么编码完成后体积会增大1/3)
举些栗子
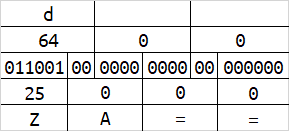
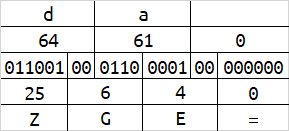
隐写的原理
base64在解码的时候,会按照字符串末尾的 = 数量来删除相应字节数。或许你已经发现了,当一组字符的数量为1字节或2字节的时候,会有4位或2位二进制在解码时被忽略,及下图的红色标识。
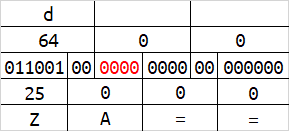
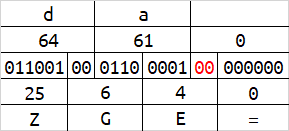
红色标识的这些二进制,能够被编码,但解码时却会被忽略。修改这些位置的内容,不会影响到原始数据。
解决问题
现在,可以来尝试解决文章开头的问题了。那组base64编码的字符串,隐藏了什么?
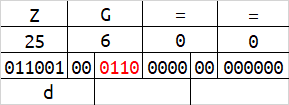
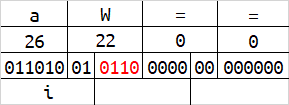
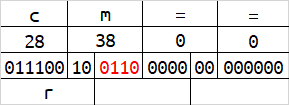
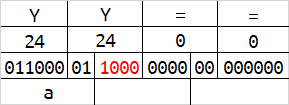
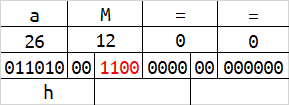
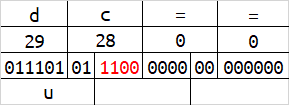

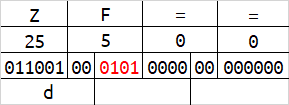
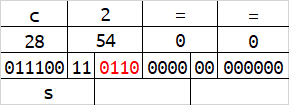

这时我们将所有红色标识的二进制位拼接起来,可以得到最后的结果为hello,现在你理解base64的编码规则了吗?
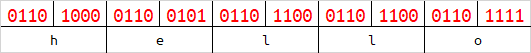
作者:兴兴
文章:Base64实现数据隐写的原理分析
链接:https://www.networkcabin.com/notes/2409
文章版权归本站所有,未经授权请勿转载。






