C#实现html和url的编码与解码
html编码的作用很容易理解,例如储存超文本编辑器的内容到数据库,一般是需要先超文本的html代码编码后进行存储,需要用到的时候就解码返回给前端。
url的编码解码一般是url中存在+-&*....等特殊符号时,浏览器会进行自动编码,保证url的可读性,一般这个url的编码与解码是使用不到的,也记录一下以防备用。
实现代码如下:
using System;
namespace ConsoleApp2
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("输入源");
string a = Console.ReadLine();
Console.WriteLine("html编码");
Console.WriteLine(System.Web.HttpUtility.HtmlEncode(a));
string b = System.Web.HttpUtility.HtmlEncode(a);
Console.WriteLine("html解码");
Console.WriteLine(System.Web.HttpUtility.HtmlDecode(b));
Console.WriteLine("");
Console.WriteLine("输入源");
string c = Console.ReadLine();
Console.WriteLine("url编码");
Console.WriteLine(System.Web.HttpUtility.UrlEncode(c));
string d = System.Web.HttpUtility.UrlEncode(c);
Console.WriteLine("url解码");
Console.WriteLine(System.Web.HttpUtility.UrlDecode(d));
}
}
}
编码和解码时也可以指定编码:
System.Web.HttpUtility.UrlEncode(str,System.Text.Encoding.Unicode);实现效果:
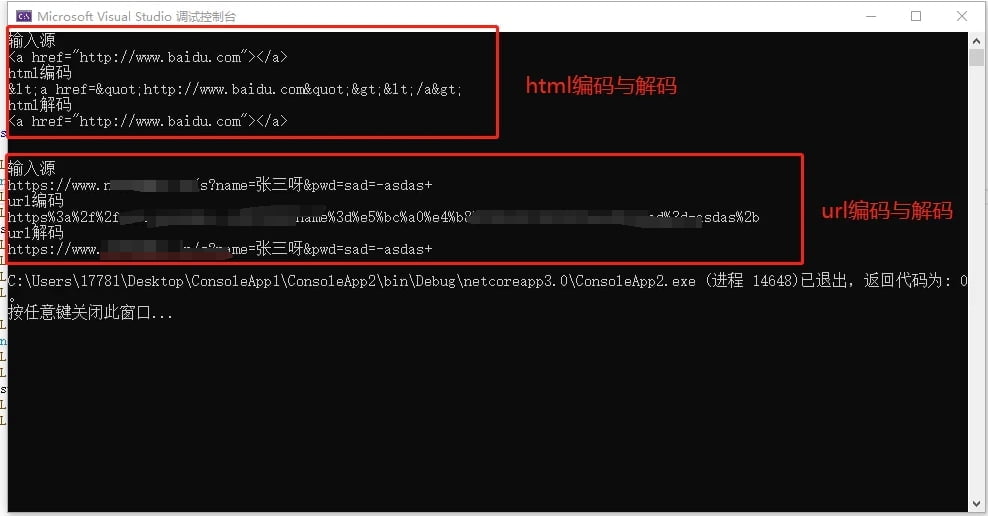
版权声明:
作者:兴兴
文章:C#实现html和url的编码与解码
链接:https://www.networkcabin.com/notes/1503
文章版权归本站所有,未经授权请勿转载。
作者:兴兴
文章:C#实现html和url的编码与解码
链接:https://www.networkcabin.com/notes/1503
文章版权归本站所有,未经授权请勿转载。
THE END






